We fine-tune 7 models including ViTs, DINO, CLIP, ConvNeXt, ResNet, on
$ 20.50 · 4.5 (648) · In stock

A Broad Study of Pre-training for Domain Generalization and Adaptation
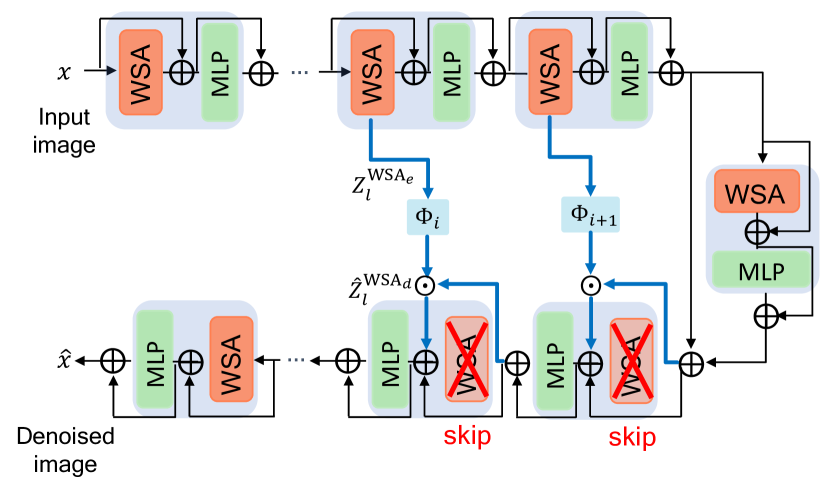
2301.02240] Skip-Attention: Improving Vision Transformers by Paying Less Attention

2301.02240] Skip-Attention: Improving Vision Transformers by Paying Less Attention

A Broad Study of Pre-training for Domain Generalization and Adaptation

Review — ConvNeXt: A ConvNet for the 2020s, by Sik-Ho Tsang
![]()
Vision Transformer (ViT)
pytorch-image-models/README.md at main · huggingface/pytorch-image-models · GitHub

Ruoqi Shen's research works

Remote Sensing, Free Full-Text

PDF] ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders

PDF) Adversarial Attacks on Foundational Vision Models
GitHub - rwightman/timm: PyTorch image models, scripts, pretrained weights -- ResNet, ResNeXT, EfficientNet, EfficientNetV2, NFNet, Vision Transformer, MixNet, MobileNet-V3/V2, RegNet, DPN, CSPNet, and more

GitHub - huggingface/pytorch-image-models: PyTorch image models, scripts, pretrained weights -- ResNet, ResNeXT, EfficientNet, NFNet, Vision Transformer (ViT), MobileNet-V3/V2, RegNet, DPN, CSPNet, Swin Transformer, MaxViT, CoAtNet, ConvNeXt, and more